

















こんにちは、カヨです。
【追加対応策の詳細と実践】
『アクセス数が急激に増えた件に対して行った対策 – ③【対応の結果と次の方針編】』の続きです。前回は、特定のドメインをブロックする対策を実施した効果を確認したところ異常なアクセスが確認されたため再調査し、追加対応策をどうするかを決めました。今回はその対応策の実践手順を見ていきましょう。
✔︎ Google Analytics(グーグルアナリティクス)を使用している人
✔︎ WEB関連の担当をしている人
✔ 異常なアクセス数に困っていて特定したい人
✔ UAブロック(怪しいボットやクローラーを弾く)を行いたい人
✔ セキュリティを試行錯誤しながらおこなっている人
📕 前提
この記事は、解決策を掲載していません。
設定などの効果などは保証しておりませんのでご了承の上お読みください。
✎ 前回のおさらい
前回は、特定の参照元ドメインからの大量アクセスをブロックしました。
その結果、一時的に状況は落ち着きましたが、数日後には「参照元情報がついていない(not set)」アクセスが急増しました。
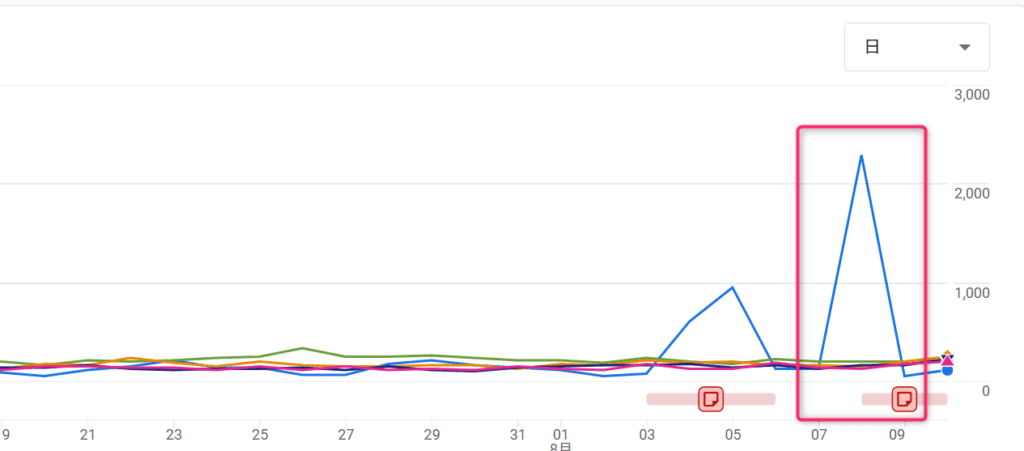
前回の方法だけでは対応できない新しい手口に切り替えられてしまった可能性が高いことがわかりました。
そこで再調査を行い、次の方針を立てることにしました。
2. すぐ効く UAブロック を入れる
3. 翌日:403が増えたか/GA4の(not set)が減ったかを確認
✔ 前回の記事はこちらから

追加対応策の詳細と実践
2. すぐ効く UAブロック を入れる
3. 翌日:403が増えたか/GA4の(not set)が減ったかを確認
では、これらの対応方法を順に実践していきましょう!
1. ログで犯人像を特定(上位IP/UA/パス/時間帯)する方法
アクセスログがあれば以下の情報がわかります。
・アクセス先 URL
・User-Agent
・件数ランキング
を集計すれば、今回の「犯人IP」や「Bot特定」ができます。今回はUAブロックをする(特定の User-Agent ブロックする)ので特定が必要ここで必須になるということですね。では、手順を見ていきましょう。
Xserver の アクセスログ 画面を開いて 異常アクセスの日のログを出す
✔ アクセス解析 > アクセスログ > 対象ドメインの「対象日」 > ダウンロードする
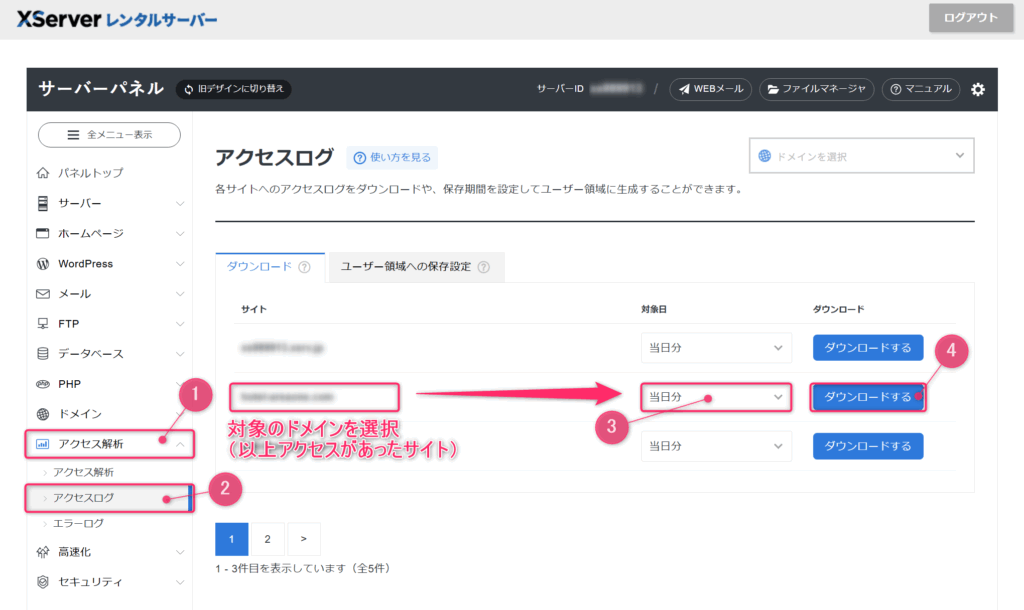
「当日分」のプルダウンをクリックして日付を選んでダウンロードボタンを押す。
これでアクセスログが出す作業が完了です。XServerは簡単にログが出せるので便利ですね!
アクセスログから特定するまで
中身はとても多いので筆者はChatGPTにきいてみることにしました。
アクセスで特に目立つのは、上位5つのIPがほぼ全アクセスの中心になっていました。
例えば1位のは 1,038件、すべてあるページにアクセスしており UA はiPhone系ですが、挙動はBot的です。
サイト全体でもいつもより多くのアクセスがあったページを計測できたのですね。今回は「/」というトップページに当たるページに異常なアクセスがあったはずです。そちらはどうでしょうか?
(トップページ)へのアクセスが多かったIPは、特に以下が目立ちます。
****IPは省略****
python-requests を使っているIP xx.xx.xxx.xxx は間違いなくBotで、即ブロックして良いレベルです。iPhone/Mac/Windows系UAも見えますが、人間の挙動とは違いアクセス回数が極端に偏っているのでBot偽装の可能性大です。
人間の操作挙動をは異なるものがあるということですね。今回の2000件以上のアクセスはどのページに集中していましたか?
2000件はHTMLページではなく、CSSやフォント関連ファイルといった静的リソースが上位に来ていました。つまり、Botが特定ページを読み込む際に、同時にCSSファイル群も大量取得しているため、表示回数が膨れています。
つまり、Botが特定ページを読み込む際に、同時にCSSファイル群も大量取得しているため、表示回数が膨れていいるのですね。
はい、もっとわかりやすく説明しますね。
▼▼▼【ChatGPTの詳しい解説】▼▼▼
Google Analytics の「表示回数」には、
・ページ(HTML)
・ページを表示するために必要な部品(CSS、画像、フォントなど)
も含まれる場合があります。
今回アクセスログを見たら、
2000回のうち大部分は「CSSやフォントなどの部品ファイル」へのアクセスでした。
🛠 どういうことかというと…
1. Botや人間がページにアクセスすると
そのページのHTML本体(例 /index.html)を読み込みます
2. HTMLの中には「見た目」を整えるためのファイル(CSS)やアイコン画像(フォント)がリンクされています
3.ブラウザやBotは、それらのファイルも自動的に全部取りに行く
その結果、「1回のページ読み込み」でも実際には5〜10回以上アクセスが発生
2000回という数字は「HTMLページ」単体のアクセスではない
実際のページ本体へのアクセスは、その数字より少ない
部品ファイルを何度も取りに行っているのは**自動化されたアクセス(Bot)**の可能性が高い
つまり、過剰にアクセスされているページに関連した部品ファイルの方がさら多く読みこまれてしまうということですね。ログを確認すると部品ファイルのアクセスの多さに埋もれてしまうけれど外部から狙われたページを知りたいときはCSSなどを排除してhtmlを確認すると特定できるということですね。
しかし、人間のアクセスではページを表示するために必要な部品(CSS、画像、フォントなど)は読まないの?
人間が普通にブラウザでページを見るときも、ページの見た目を作るために必要な部品(CSS、画像、フォントなど)はちゃんと読み込みます。
じゃあ、なにが違うのか詳しく説明しましょう。
▼▼▼【ChatGPTの詳しい解説】▼▼▼
違いは「アクセスの仕方と量」です。
👥 人間のアクセス 👥
・ページ(HTML)を開くと同時に、そのページで必要なCSS・画像・フォントを一度だけ読み込む
・同じページを何回も連続で開くことは滅多にない
・ブラウザがキャッシュ(保存)してくれるので、2回目以降はCSSや画像は再取得しないことが多い
🤖 Botのアクセス 🤖
・ページ本体とCSSや画像を毎回サーバーから取りに行く
・キャッシュを使わず、何百回も同じ部品を要求する
・ページ表示のためではなく、単純に全部ファイルを取ることが目的の場合もある(スクレイピングや負荷テスト、調査Botなど)
🐟 今回の2000件の動き 🐟
⇒ 普通の人間なら最初の数回だけ取得して終わるCSSやフォントを何百回も取得している
⇒ これは「キャッシュ無効」で連続リクエストを送るBotの典型挙動
つまり、人間も部品は読むけど、回数やパターンでBotかどうかが分かるということです。
今回のは明らかにBotのパターンです。
このあとこのbotアクセスを防ぐための動きはなにをしたらいの?
以下のこの流れなら、今回の(not set)アクセスを明日から激減させられます。
・対象日のアクセスログから 今回のBot IPリスト作成
・
.htaccess または Xサーバー管理画面で IP拒否・ 追加で User-Agentフィルタ
T 再びアクセスログ・GAで効果を確認
では予定してた対応に今回のBot IPリスト作成とIP拒否も入れて対処していくことにしましょう!
1.5. Bot IPリスト作成とIP拒否
2. すぐ効く UAブロック を入れる
3. 翌日:403が増えたか/GA4の(not set)が減ったかを確認
1.5. Bot IPリスト作成とIP拒否 する方法
IPリスト作成
こちらはアクセスログファイルから上位IPを元にChatGPTにリストを作成してもらいました。
大量のデータを分析するのはお任せください!
IP拒否設定
✔ Xserver の .htaccess 設定の編集画面を開く
✔.htaccess 設定の編集
⇒ 以下のコードを追記
<RequireAll>
Require all granted
# 下記のIP部分を、実際にアクセスログで確認した不正アクセス元に置き換えてください
Require not ip xxx.xxx.xxx.xxx
Require not ip yyy.yyy.yyy.yyy
Require not ip zzz.zzz.zzz.zzz
</RequireAll>これで「IPブロック(確定ボット中心)」ができました。今回の犯人をピンポイントで止めます(必要な分だけ)
2. すぐ効く UAブロック を入れる 方法
偽装してないUAベースのボット遮断をできます。「アクセスしてきたブラウザやツールの名前(UA)を見て、怪しいやつだけ門前払いする」仕組みです。
✔ Xserver の .htaccess 設定の編集画面を開く
⇒ IP拒否設定と同じ画面
✔.htaccess 設定の編集
⇒ 以下のコードを追記
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (python-requests|curl|wget|libwww-perl|httpclient|okhttp|scrapy|spider|crawler|HeadlessChrome|java) [NC]
RewriteRule ^.*$ - [F,L]RewriteEngine On が既にこの記述より上に書いてあれば必要ありません。
コード解説
python-requests|curl|wget|...
→ ここに列挙したのは、普通の人は使わないツールやBotの名前・
[NC]
→ 大文字・小文字を区別しない(No Case)・
[F]
→ 強制的に403 Forbiddenを返す(アクセス拒否)・
[L]
→ これが最後のルールとして処理を止める(Last)・IPアドレスみたいにコロコロ変わる相手にも効く
・サイトの正規ユーザーには基本影響なし(普通のブラウザUAにはヒットしない)
・賢いBotはUAを偽装する(「Mozilla/5.0」とだけ名乗るなど)ので、全部は防げません
・偽装対策は、次の段階でIPブロックやアクセス頻度制限と組み合わせると効果大
これを入れるだけで、今回の python-requests 型Bot は即時遮断できます。
基本的には普通のお客様は遮断しません。 今回のUA(ユーザーエージェント)ブロックで指定しているのは、 明らかに「人間がブラウザでサイトを見ている時には絶対使わない名前」だけです。
設置後チェック
✔ 安全運用チェック
① バックアップ:.htaccess をローカル保存
② 反映:追記してアップロード
③ 動作確認:サイトの数ページを通常ブラウザで開く(問題ないはず)
✔ 効いてるか超速テスト
手元で実行できる人向け:
curl -I -A "python-requests/2.31.0" https://あなたのドメイン/
# → HTTP/1.1 403 Forbidden が返れば成功ここまでで追加対応の設定は完了しました!この設定がしっかり異常なアクセスを抑えることができている経過観察をしておきましょう◎
3. 翌日:403が増えたか/GA4の(not set)が減ったかを確認
確認方法ですが最初の記事で行った方法と同じですので、もし忘れてしまった方は以下からご覧ください!

筆者はこの対策をすると翌日からその後はアクセス数が急に増えることはなくなりました。しばらくは観察を続けましたがいまだに異常なアクセスにはなっていません。こうした対策は実際にきいているのかというのはテストや後日観察でログなどを確認してわかります。今回はここまでです。また何かあれば、記事にしていこうと思います。
その他
これまでの設定以外にもさらに調べるとまだまだ設定できそうなセキュリティがありました。
追加で高度な防御設定 「WAF」
✔ WAF (Web Application Firewall)とは
Webアプリケーション専用のファイアウォールのこと。
普通のFW(ポート制御)は「どの通信を通すか/通さないか」ですが、
WAFは リクエストの中身(URL・パラメータ・Cookie・ヘッダなど)を解析して、不正っぽいものをブロックします。
【XServer のWAFの特徴】
オン/オフ切り替え式(管理画面でボタン一発)
攻撃っぽいリクエストは自動で遮断し、ログに残る
過検知(正規のリクエストを間違って弾く)もあるので、その場合は「除外設定」か「一時オフ」にすることもできる
今回設定した .htaccess のでやってるのは「UAで弾く」「特定IPを拒否」などシンプルな条件付きアクセス制御。WAFは「リクエストの中身まで深く検査」してくれるので、アプリ脆弱性攻撃の防御に強い。.htaccess は「自分が把握してる怪しいアクセスのブロック」、WAF は「知らない攻撃も幅広くカバー」。両方あればベストだそうです。
✔ WAF (Web Application Firewall)設定
⇒ セキュリティ > WAF設定 > 設定状況
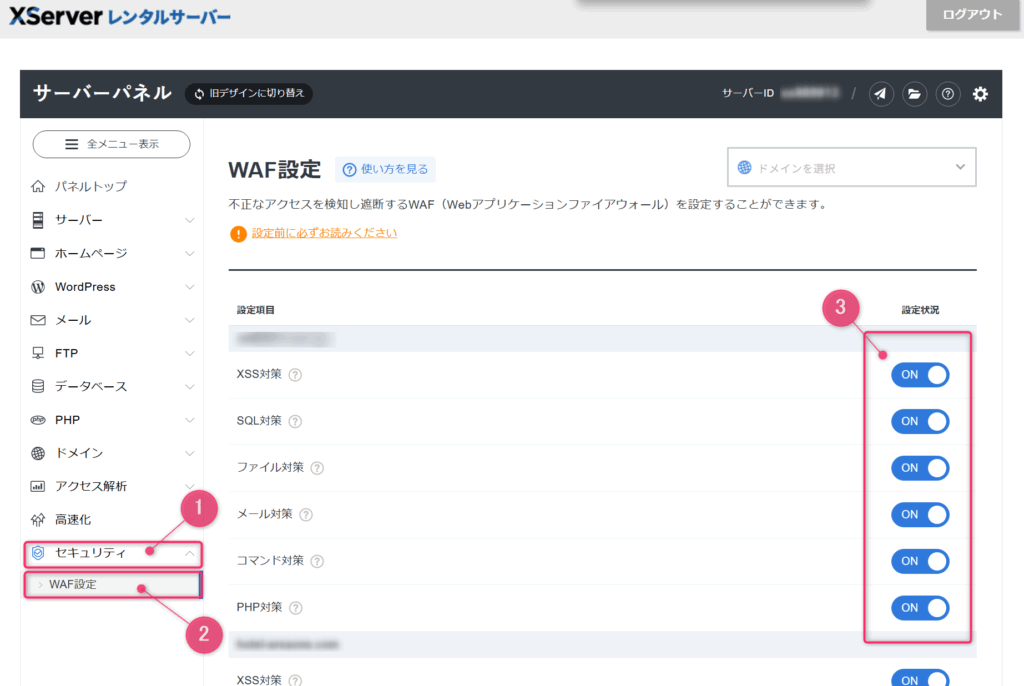
XServerにあるWAFは、XSSやSQLインジェクションを自動で弾いてくれるセキュリティ機能。.htaccess の制御とは役割が違うので、基本はONのままで、もし誤検知が出たときだけ調整すればOK。
✔ WAFの「過検知」
WAFは「攻撃っぽい文字列」を検知して止めます。でもそれが本当は正規リクエストでも「危険」と判断してはじかれることがあります。これが 過検知(false positive)です。
機能(お問い合わせ、ログイン画面、外部サービスとの連携など)に影響がでてはじかれてしまうことも…。なので設定後は必ず正常に動いてるかも確認してみてください。
実は、私もWAF設定はじかれてしまいました💦
ChatGPTはWAF設定ではじかれてしまうようです。WAFは正規の通信も誤検知することがあるので、状況に応じて調整が必要です。
ChatGPTがはじかれてしまうということから.htaccessもにもそのための設定を追記することにしました。
【 .htaccess 設定 】Google検索 & AI学習クローラー許可
遮断したくないものを指定しておく記述を書いておくと安心です。以下の記述を追加します。
RewriteEngine On
# --- Google検索 & AI学習クローラー許可---
RewriteCond %{HTTP_USER_AGENT} (Googlebot|GoogleOther|Google-InspectionTool|Storebot-Google|AdsBot-Google|Google-Extended|bingbot|CCBot|ClaudeBot|Anthropic|PerplexityBot|GPTBot) [NC]
RewriteRule ^ - [L]# UAベースのボット遮断
RewriteCond %{ENV:ALLOW_STAGING} !=1
RewriteCond %{HTTP_USER_AGENT} (python-requests|curl|wget|libwww-perl|httpclient|okhttp|scrapy|spider|crawler|HeadlessChrome|java) [NC]
RewriteRule ^.*$ - [F,L]ただしWAF設定があればWAF設定でブロックされてしまいますので、合わせて確認を👍
✔ 確認テスト
◆ UAブロックが効いてるか
curl -I -A "curl/8.0" https://あなたのドメイン/ # 403 になる想定◆ クローラー許可が効いてるか
curl -I -A "Googlebot" https://あなたのドメイン/ # 200(以降のRewriteをスキップ)
.htaccess の並び
設定の順番は何をどう効かせたいかで変わってきたり、順番によっては効かなくなったりします。この優先順位は人それぞれその時々なので備忘録までに。今後もどんどん追加したり変更していくのでまた都度変わる可能性があります。別の設定もはいっているのでご了承ください。
# ▼ 設定順の目安(例) ▼
# 1. HTTPS化
# 2. www付きURLの統一
# 3. 正規クローラーの許可
# 4. UAベースのボット遮断
# 5. 特定IPアドレスのブロック
# 6. 特定ドメインからのアクセス遮断
【メモ】
RewriteCond %{ENV:ALLOW_STAGING} !=1を「# UAベースのボット遮断」「# — 指定ドメイン からのスパムアクセスをブロック—」の最初に追加
※順番がわかればいいのでコメントアウトの中の内容は省略しています。
この辺りは改善していく余地ありなので、さらに理解を深めていきましょう!
注意事項
「アクセス数が急激に増えた件に対して行った対策 」は以上です!
お疲れ様でした🎉

この記事が少しでも参考になれば嬉しいです。こうした役に立つようなIT関連の記事を更新していきますので、ブックマークやお気に入りにしておいてくださいね。♡もクリックしてもらえると励みになります☺

